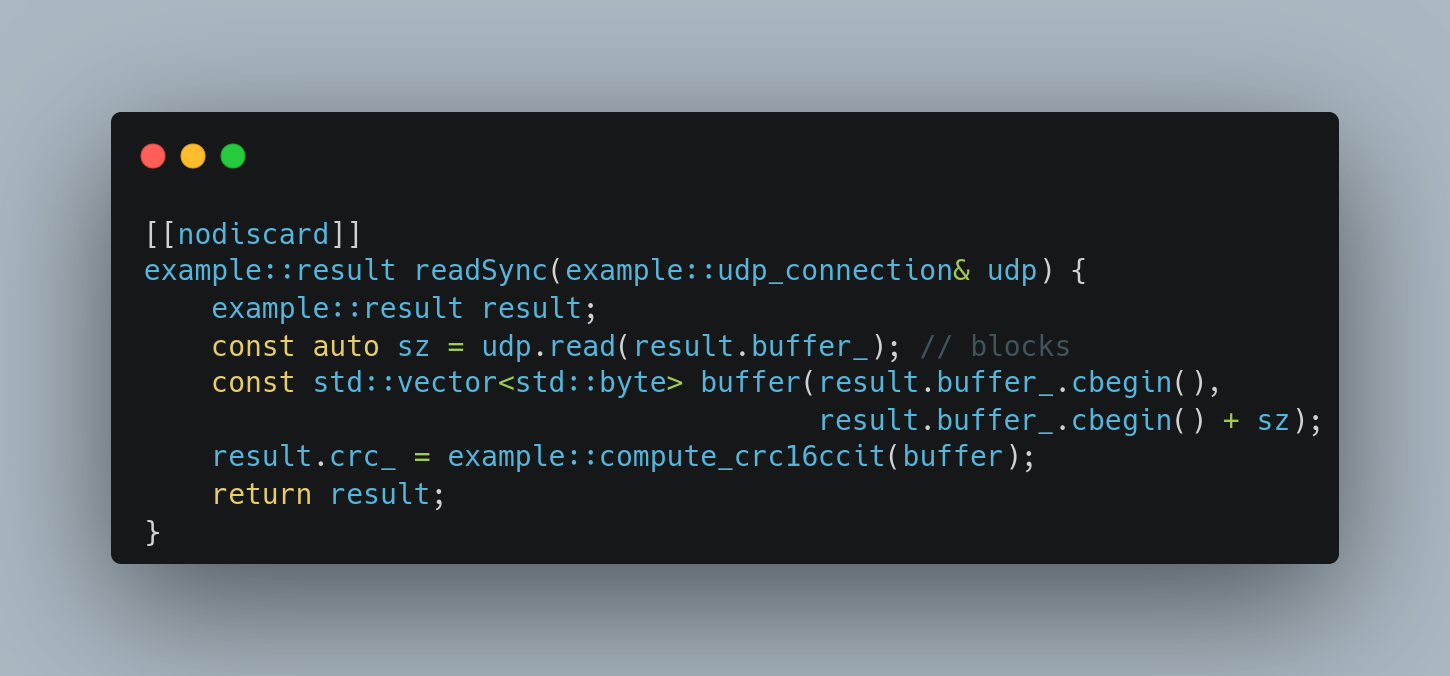
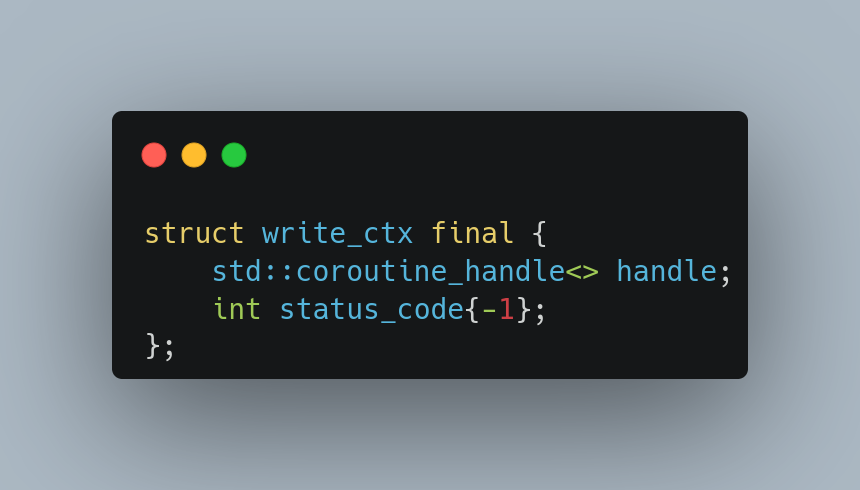
This month we hosted Rich Yonts, the author of a Manning publication title (MEAP/Beta) – 100 C++ Mistakes and How to Avoid Them
The recording can be found in our San Diego C++ Meetup channel:
The meetup even link can be found here.
About Rich Yonts:
Rich Yonts is a Senior Software Engineer at Teradata and a long-time software engineer using C++, Java, and Python. Rich held a number of technical and leadership roles during his many years at IBM and Sony. As an assistant professor, he has dealt with questions and issues of undergraduate and graduate students learning programming. He has deep experience on large code bases and considers himself both a student and a teacher of C++.
Rich cherry-picked few examples from the book and presented to the group.
Here is the summary of the topics:
- The challenges when dealing with old codebase in various companies. i.e. dealing with 98/03 and not beyond that.
- Narrowing values, uniform initialization to detect narrowing.
- Referring to an uninitialized data member and UB.
- Post vs pre increment of type instances.
- The fit fall of using setter when class invariant is not checked/violated and how to solve it.
- Shallow vs deep copy and how to ensure a deep copy with copy constructor and op=.
- The benefit of using the “override” keyword.
- Using “=delete” keyword to disable a specific function, vs the old 98/03 “method”.
- Variadic Templates.
- Using sprintf vs iostream vs std::format.
That’s it for June 2024 session.
Thank you for reading!
Kobi