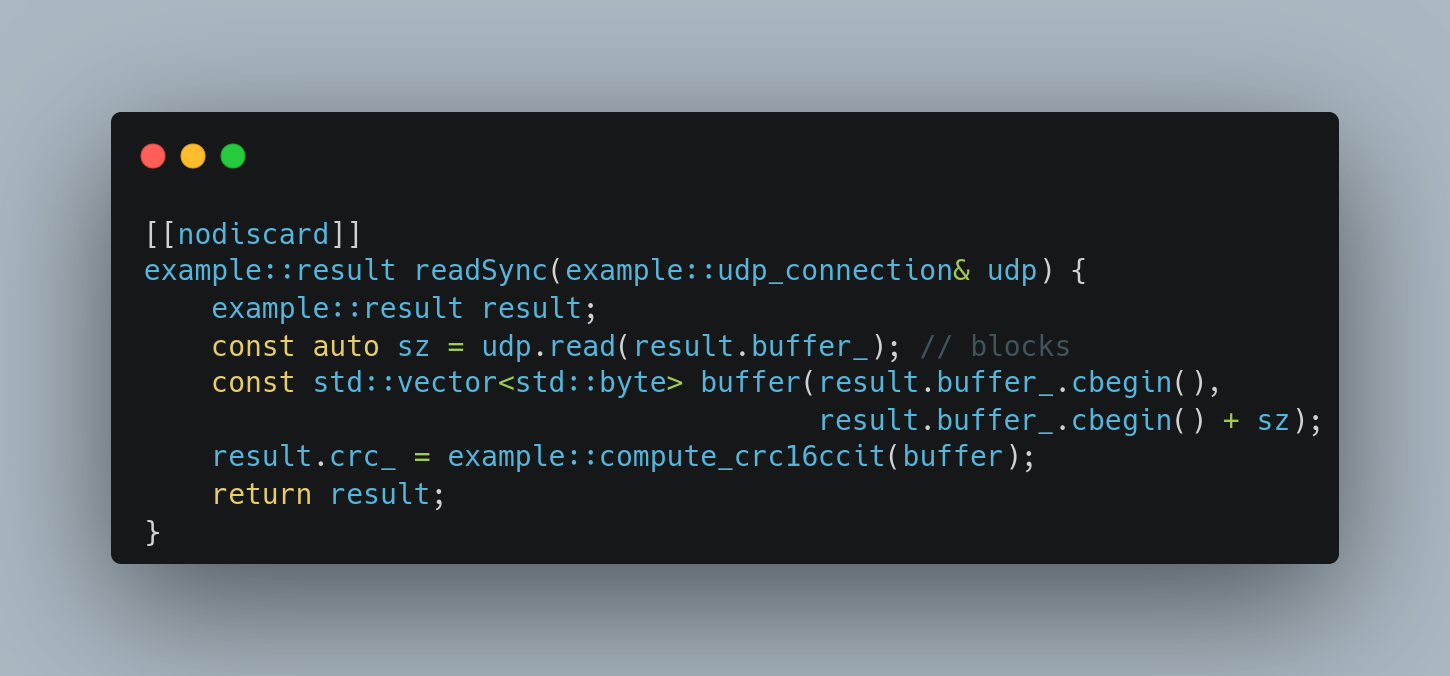
Hello everyone,
Last Tuesday (September 17, 2024), we gathered for the 66th meeting of The San Diego C++ Meetup.
The topic was CMake. Yes, CMake can be fun sometimes! 😊
The inspiration for this session came from the relatively new 2nd edition of “Modern CMake for C++” by Rafal Swidzinski.
First off, the book is fantastic! It’s packed with valuable material that can make your life easier if your build system is CMake. Despite considering myself quite knowledgeable about CMake, I learned a lot from it.
This wasn’t my first time giving a talk on CMake. I’ve had several opportunities in the past, ranging from one-hour to multi-hour sessions. It always feels like there’s so much to cover that even 1, 2, or 4 hours isn’t enough to touch on every aspect of CMake. CMake is extensive, and it’s crucial to understand and use it well. Otherwise, your build system can become difficult to improve, extend, and maintain, leading to a lot of frustration.
When discussing CMake (or any topic in a C++ session), my goal is for everyone to learn something new—at least one thing!
The meetup page link: here
And the recording:
BTW – We had an excellent session on July 11, 2023, with Alex Reinking, titled “Modern CMake Best Practices for Library Authors” at the San Diego C++ Meetup. It’s definitely worth watching!
Summary of our discussion:
- Introduction to the book.
- CMake’s popularity (based on 2023 surveys).
- Overview of CMake: its purpose and stages (configuration, generation, and build).
- Simple CMake files and FetchContent.
- Generators: what they are and how to write agnostic command lines that work with any generator.
- CMake Cache file (CMakeCache.txt): using the --force option, cache variables, and debugging/tracing CMake build generation with options like --trace, --log-context, --trace-expand, and --debug-output.
- Cleaning with the --clean-first option.
- Targets: what they are and how to build them.
- Installation: a high-level overview (there’s much more to explore here).
- Running CMake as a script with the -P option.
- Brief mentions of CTest/CPack and other tools in the CMake suite.
- CMakeConfigureLog.yaml (introduced in version 3.26) for advanced debugging of the configure stage.
- Utility modules included with the CMake package, and projects like cmake-awesome and cmake-modules.
- Find modules.
- A slide on important elements of the CMake language (the book has an excellent chapter on this).
- CLion and CMake: debugging CMake with CLion.
Additional topics covered in the book:
- Generator expressions
- Dependency graph and how to print it
- CMake presets
- Program analysis tools
- C++20 modules
- Testing frameworks
- Generating documentation
Many thanks to Packtpub for their support providing me the material to review!
That’s it for this session!
Happy CMake-ing!
Kobi